
You could have been playing with this concept so many times without knowing the name of ETL. Let have a quick concept review using MovieLens automation as examples.
Concept
According to Wikipedia: Extract, Transform and Load (ETL) refers to a process in database usage and especially in data warehousing that:
- Extracts data from homogeneous or heterogeneous data sources
- Transforms the data for storing it in proper format or structure for querying and analysis purpose
- Loads it into the final target (database, more specifically, operational data store, data mart, or data warehouse)
ETL helps organizations to make meaningful, data-driven decisions by interpreting and transforming enormous amounts of structured and unstructured data. The need for ETL has increased considerably, with the upsurge in data volumes.
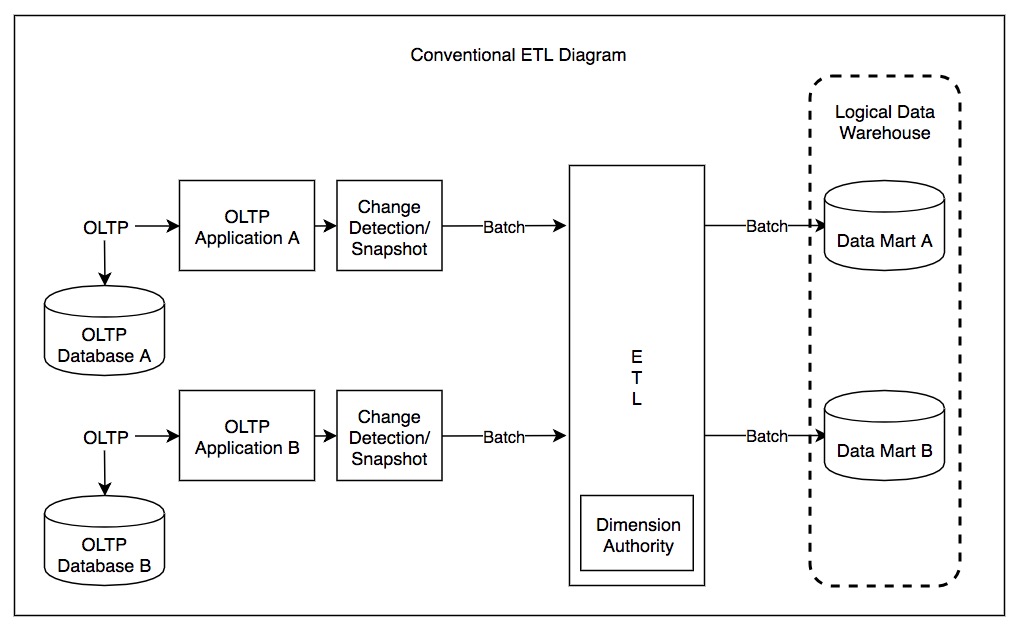
ETL Process:
ETL processes have been the way to move and prepare data for data analysis. The ETL process involves the following tasks:
Extracting the data
This is the first step in the ETL process. It covers data extraction from the source system and makes it accessible for further processing. The main objective of the extraction step is to retrieve all required data from the source system with as little resources as possible.
The extraction step should be designed in a way that it does not negatively affect the source system. Most data projects consolidate data from different source systems. Each separate source uses a different format. Common data-source formats include RDBMS, XML (like CSV, JSON) . Thus the extraction process must convert the data into a format suitable for further transformation.
As an example, I reuse the Movielens processing.
# Download the file from `url` and save it locally under `file_name`:
dt_name = os.path.basename(datasets[dt])
print('Downloading {}'.format(dt_name))
with urllib.request.urlopen(datasets[dt]) as response, open('./sample_data/'+dt_name, 'wb') as out_file:
shutil.copyfileobj(response, out_file)
print('Download completed')
#Downloading ml-100k.zip
#Download completedTransforming the data
This may involve cleaning, filtering, validating and applying business rules. In this step, certain rules are applied to the extracted data. The main aim of this step is to load the data to the target database in a cleaned and general format (depending on the organization’s requirement). This is because when the data is collected from different sources each source will have its own standards.
For example, if we have two different data sources A and B. In source A, the date format is like dd/mm/yyyy, and in source B, it is yyyy-mm-dd. In the transforming step, we convert these dates to a general format. The other things that are carried out in this step are:
- Cleaning (e.g. “Male” to “M” and “Female” to “F” etc.)
- Filtering (e.g. selecting only certain columns to load)
- Enriching (e.g. Full name to First Name, Middle Name, Last Name)
- Splitting a column into multiple columns and vice versa
- Joining together data from multiple sources
In some cases, data does not need any transformations and here the data is said to be “rich data” or “direct move” or “pass-through” data.
As an example, refer to the MovieLens automation article:
#Check user data
usrdata.head()| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 |
| 1 | 186 | 302 | 3 | 891717742 |
| 2 | 22 | 377 | 1 | 878887116 |
| 3 | 244 | 51 | 2 | 880606923 |
| 4 | 166 | 346 | 1 | 886397596 |
#check data integrity
usrdata.isnull().any()
#user id False
#age False
#gender False
#occupation False
#zip code False
#dtype: boolLoading the data
Data is loaded into a data warehouse or any other database or application that houses data. This is the final step in the ETL process. In this step, the extracted data and transformed data is loaded to the target database. In order to make data load efficient, it is necessary to index the database and disable constraints before loading the data.
The following example saves data from a data frame to libfm format and ready to fetch in a machine learning model.
def save_to_libfm(data_frames, out_file_names, target='rating', outdir='./sample_data/processed/'):
if not os.path.exists(outdir):
os.mkdir(outdir)
assert len(data_frames)==len(out_file_names), "number of dataframes must equal number of file names"
for i in range(len(out_file_names)):
dump_svmlight_file(data_frames[i][['userId', 'movieId', 'timestamp']],data_frames[i][[target]].values.ravel(), outdir+out_file_names[i],zero_based=True,multilabel=False)To sum up
Obviously, ETL is just a fancy term that you often play with when handling data. In many cases, the three steps in the ETL process can be run parallelly. Data extraction takes time and so the second step of the transformation process is executed simultaneously. This prepares data for the third step of loading. As soon as some data is ready it is loaded without waiting for the completion of the previous steps.
